Размышления о статистике на примере аккаунта в Директе Газпромбанк Автолизинг

Введение
Работая с Performance каналами рекламы, часто можно встретить такие вопросы:
- Новая кампания работает уже 3 дня, где конверсии?
- Почему на позапрошлой неделе было 150 конверсий, а на прошлой только 100? (и наоборот)
Эти и прочие подобные вопросы исходят из желания рекламодателя получить мгновенный результат. «А стульчики когда будут? Утром – деньги, днем – стулья». На практике, статистические колебания на небольших объемах данных столь велики, что шансы получения диаметрально противоположных результатов отнюдь не крошечные. Как и шанс не получать результат вообще какое-то длительное время.
А почему так происходит и зависимость не линейная?
Типичный рекламодатель сталкивается с тем, что выкупает конкретной рекламной кампанией очень небольшой процент аудитории и не способен получать по такой маленькой выборке стабильно положительный результат.
Можно упростить все до мысленного эксперимента с полем для морского боя, где есть аудитория (100 секторов) и в среднем 1% этой аудитории (использовалось случайно сгенерированное число от 1 до 100, где 1 – это искомая нами аудитория с горячим спросом) готов сегодня совершить конверсионное действие. Для упрощения выкупаемая в нашей фантазии доля расположена в одном месте и обозначена жирной линией границы. Результат генерации ниже и в целом отражает классическую поговорку:
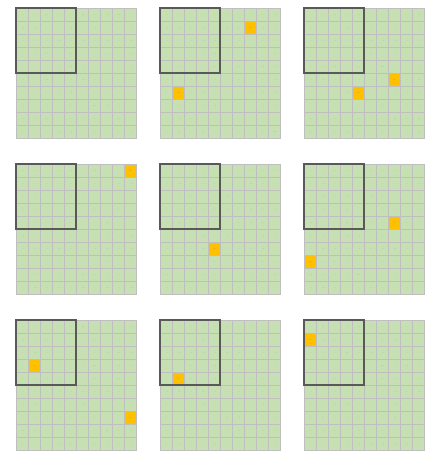
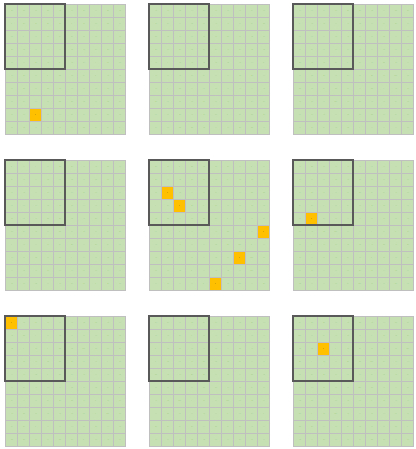
Естественно, что доля именно случайных флуктуаций меньше, чем влияние огромного множества факторов, но пока у нас нет демона Лапласа (или какой чудо-нейросети из будущего ChatGTP-2099), мы не можем создавать точный алгоритм и даже достаточно точно описать исходное состояние системы, а, скорее всего, даже не знаем всех факторов, на неё влияющих.
При этом есть простые и эффективные предсказательные модели, которые могут помочь с оценкой текущих результатов, с предсказанием будущих и даже иметь неожиданные интерпретации.
Практика
Давайте вернемся к исходным типовым вопросам клиентов из введения. Попробуем на примере клиента с относительно большим количеством статистики сделать какие-то эмпирические заключения. Возьмем для этого аккаунт Газпромбанк Автолизинг в Директе – стабильный по результативности и с большим объемом данных, где сотни рекламных кампаний на длительном отрезке дают нам возможность пусть не говорить о статистической закономерности, но о получении репрезентативного результата.
Для начала давайте посмотрим, как отрабатывают новые запуски на результат. Для этого возьмем 50 запусков и на временной шкале установим количество кампаний, которые принесли первую конверсию в определенный отрезок времени:
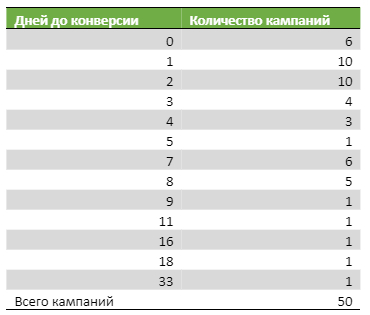
Думаю, вы согласитесь, что пока статистика выглядит неубедительно. Несмотря на то, что первые три дня явно преобладают, нам нужно большее количество замеров для уверенности. Возьмем 150 кампаний:
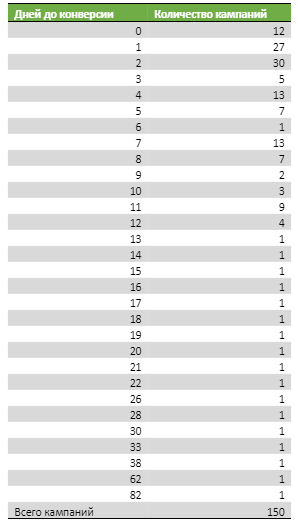
Так намного лучше. Уже можно говорить о том, что отсутствие результата в первые две недели – тревожный звонок. Ясно, что какие-то направления будет желание продолжать рекламировать из стратегических соображений, но можно остаться с оплатой за конверсию в ожидании лучших внешних или внутренних условий и не тянуть ресурсы. При этом, если речь об оплате за клики, то в данном случае мы уверенно можем говорить, что 12-ти дней достаточно, чтобы появился результат.
Визуализируем для наглядности?
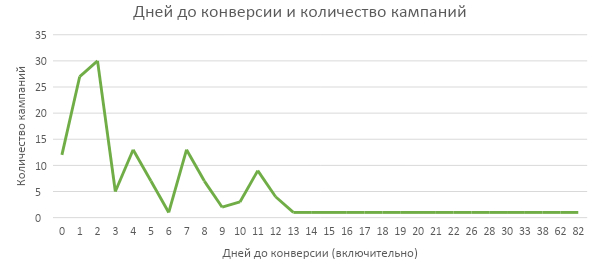
График «ершистый», т. к. даже 150 кампаний – это немного. Но ведь нам и не нужна вероятность конкретно в 3-й или 7-й день, поэтому мы можем использовать интервалы или накопительный итог. Накопительный итог выглядит предпочтительнее, т. к. перед собой мы ставим обычно срок ожидания в днях (до десяти дней), а не в конкретном периоде (получить на второй неделе).
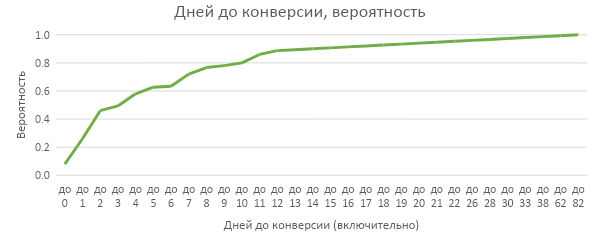
Давайте посмотрим, что получилось:
- провал в начале графика «до 0» обусловлен модерацией/активацией рекламных кампаний в первый день работы, кампания просто не успевает выкупить трафик на доступный бюджет;
- 2/3 кампаний «выстреливают» в первую неделю работы;
- почти 90% кампаний приносят конверсии в первые две недели работы, вероятно, этого времени достаточно, чтобы сгладить все возможные негативные факторы, набрать достаточный объем кликов и дать время для стабилизации работы стратегии;
- после 12 дней выходим на плато (в том числе и потому, что ресурсы в подобные кампании минимизируются).
Казалось бы, что все логично, но чем меньше объем запусков и бюджет, тем болезненнее каждая неудача и вероятнее большое количество идущих подряд пустых запусков. Очевидно, что нужно соотносить объем выделенных средств/получаемого трафика со скоростью получения результата, однако время тоже необходимо как для обучения стратегий, так и для сглаживания возможного влияния внешних факторов (спрос зачастую цикличен даже внутри месяца).
А что тем временем с конверсиями?
Мы запустили рекламную кампанию, получили первые результаты и накапливаем их, и здесь возникают вопросы с объемом. Эти вопросы тем тяжелее, чем уже тематика. Но, взяв за основу совокупный результат, мы можем посмотреть, насколько визуально разные результаты являются предсказуемыми. Если мы посчитаем сигму (стандартное отклонение) – величину, характеризующую меру разброса случайной величины, – то окажется, что все наши значения находятся в пределах двух сигм, что соответствует ~95% значений в нормальном распределении.
Геометрический смысл брать 1/2/3 сигмы можно понять на графике ниже, где представлено нормальное распределение случайных величин: на оси абсцисс отложены от нуля 1/2/3 сигмы, на оси ординат – частота, а закрашенная площадь соответствует вероятности встретить измеряемые значения в этой области.
Графики ниже составлены за год на всем объеме лидов в Яндекс.Директе. Большинство значений попадет в границы одной сигмы, в 2 сигмы попадут все значения.
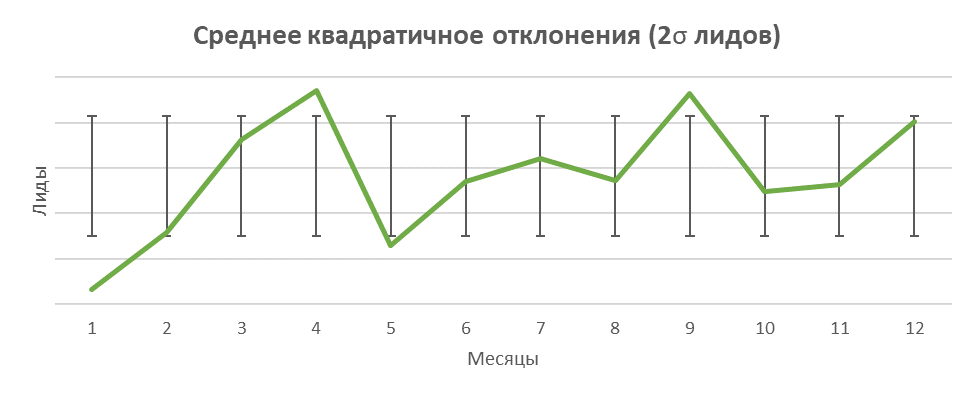
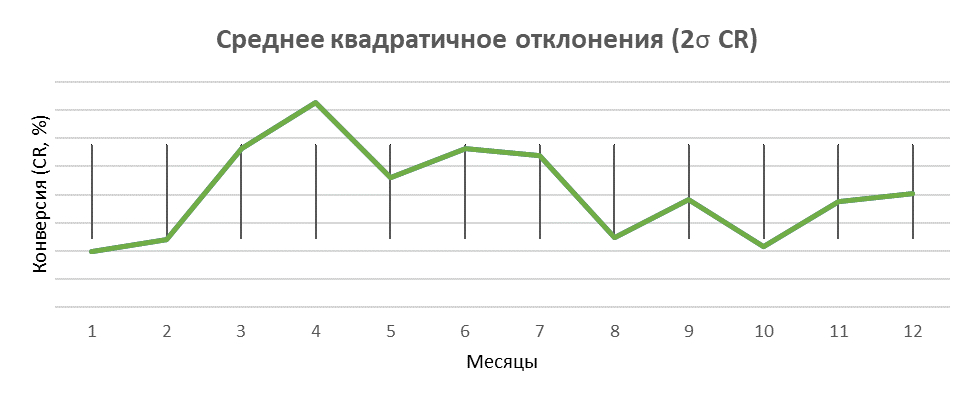
График по проценту конверсии корректнее характеризует общую картину колебаний, т. к. количество прямо связано с бюджетом.
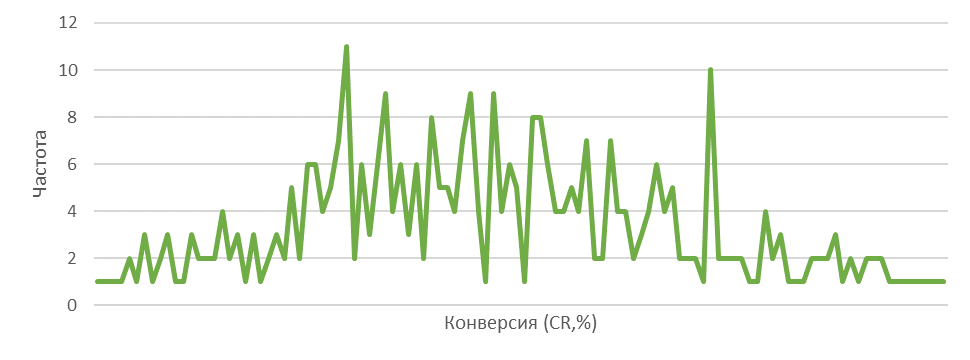
При переходе к конкретному направлению, например, все РК по спецтехнике или к марке, ситуация будет катастрофически усложняться, но все-таки и она поддаётся осмыслению. С этим нам поможет распределение, для которого мы возьмем данные по дням за год. При округлении до 4 знаков после запятой мы получили 110 уникальных значений. Конечно, это снова «расческа», а не поддающийся чтению график.
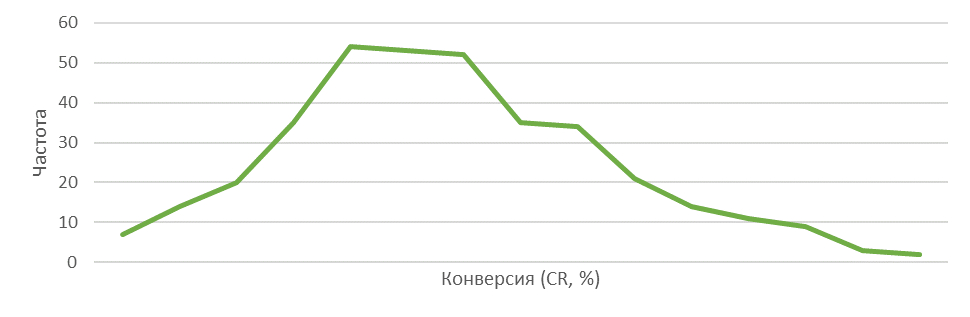
Округлим до 1 знака после запятой и получим «нормального» вида распределение с легкой асимметрией:
Такой ряд даёт возможность посчитать вероятность:
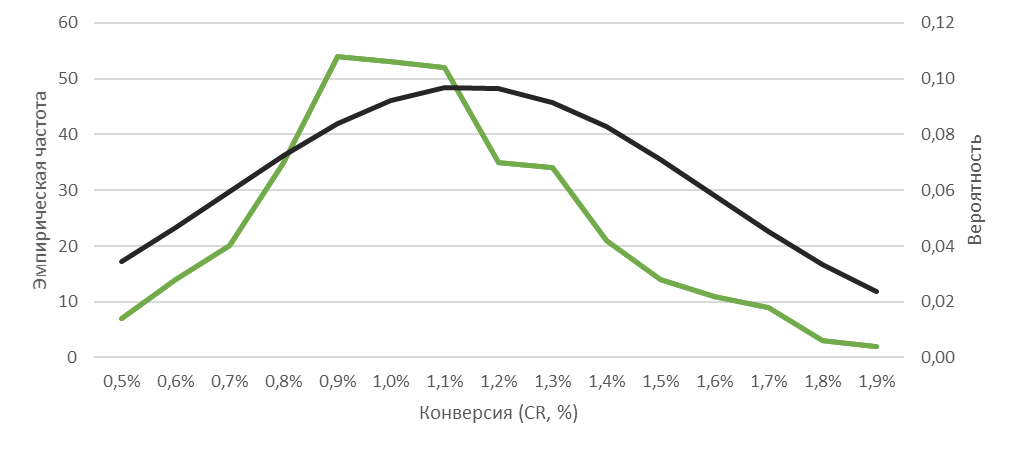
В итоге на графике хорошо видно, что вероятность получения крайних значений не так уж и мала, а крайних низких заметно выше, чем крайне высоких.
Эксперимент
Закончить рассказ хочется практической демонстрацией. Подопытным кроликом стал АА-тест, который будет накапливать результат и постепенно получит… статистически значимые различия с исходной кампанией (или нет?). Для этого была выбрана стабильно приносящая конверсии кампания по одной из марок спецтехники. Аудитория была разделена стандартным функционалом экспериментов.
Обычный специалист, как правило, предоставлен самому себе в оценке результатов своих трудов. В момент, когда требуется решать задачи подобные нашему сравнению двух кампаний, маркетологу обычной кампании не помогают data-аналитики, некому внести ясность по методу, которым тестировать данные (подобрать подходящий критерий – метод проверки гипотез), некому валидировать метод на большом количестве реальных или смоделированных данных и, наконец, строго, одинаково и беспристрастно интерпретировать результаты. Специалист чаще всего остается один на один с бесчисленными статьями о проведении тестов, в которых предлагается пользоваться бесконечными калькуляторами объема выборки, а рассматриваются, как правило, два основных метода – это t-критерий Стьюдента и U-критерий Манна — Уитни.
Давайте начнем с самого популярного критерия – T test. Здесь сразу возникает проблема – полученные результаты не проходят проверку на нормальность распределения, мы не можем использовать T-test. Это и есть первый этап анализа, который игнорируется кампаниями, где маркетолог и швец, и жнец, и на дуде игрец. Я поступлю также, чтобы не портить историю.
В таблице результатов исходная кампания будет обозначена как 1, тестовая – как 2.
На следующий же день после создания копии, в первый день работы после модерации, дубликат прилично обставил в эффективности оригинал, вероятно, благодаря пробам разной аудитории алгоритмами Директа. Впоследствии результаты нормализовались, и крайне высоких значений не появлялось до самых последних дней двадцатидневного теста.
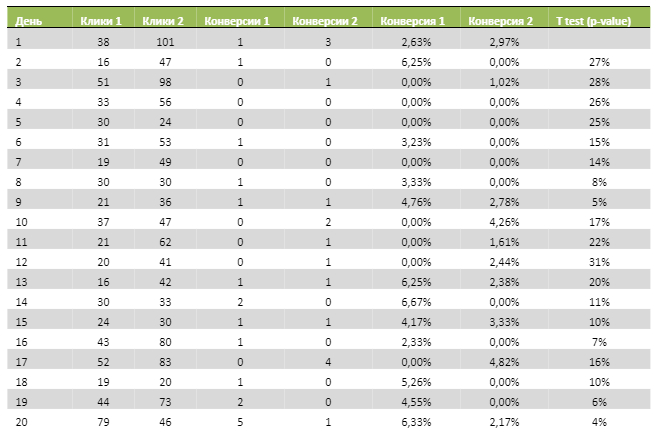
Итак, наша нулевая гипотеза состоит в том, что кампании идентичны (средние значения конверсии будут равны). Альтернатива гипотезе – что у кампаний есть обусловленные какими-то факторами различия, влияющие на значение конверсии.
Уровень значимости (𝛼) я выбрал равный 10% (научным стандартом считается 5%). Для нашего двухвыборочного t-теста данный уровень будет достигнут в 30% случаев (на 8-й день мы могли бы закончить тест и получить p-значение ниже уровня значимости). Это значит, что, завершая тест в один из 6 дней, где значение p меньше 10%, мы должны с вероятностью 90% принять факт, что у кампаний есть различия. Дополнительно, если мы следим за результатом в динамике, сработает ошибка подглядывания, о которой можно подробно посмотреть у аналитика Анатолия Карпова. Суть её в том, что, наблюдая накопительный результат и тренд к снижению накопленного p-значения с первого по девятый день, мы, вероятно, отключили бы тест в 9-й день, заключив, что нулевую гипотезу можно отвергнуть с очень высокой вероятностью. Забавно, что в итоге границу в 5% удалось пробить дважды, а главное – получить меньшее значение именно к завершению теста.
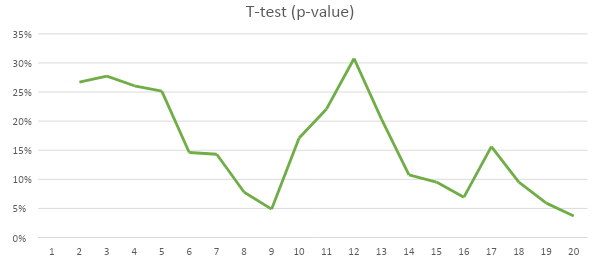
С дальнейшим накоплением данных ситуация не становится проще, и к двадцатому дню мы снова падаем за границу 5%. Здесь справедливыми будут возражения, что исходный объем довольно небольшой. Но это как раз те типичные объемы бюджета и конверсий, которыми оперируют в тестах огромного числа проектов. При этом в моменте с самым низким значением, рассчитав сводные показатели кампаний, окажется, что CPL в нашем примере различается на 40 рублей. Даже ориентируясь на самую частую мантру бизнеса про максимум лидов за меньшие деньги, можно сказать, что кампании, различающиеся на 1% по цене лида, для менеджера будут равнозначны. Волею алгоритмов и случая в новой кампании клики были дешевле, а на большем сроке наверняка стремились бы к общей средней.
Теперь выясним, что будет происходить с тестом при использовании U-критерия Манна – Уитни, который подходит для малых выборок, не соответствующих критериям нормальности. Смысл критерия в том, что оценивается степень пересечения значений, а не сами значения (медианы). Для оценки каждому значению присваивается ранг, формируется таблица рангов, что позволяет произвести необходимые расчеты. Конечное значение сравнивается с критическими значениями из специальных таблиц, где по осям находится количество значений в выборках, а сами таблицы разные для разного уровня значимости. Выглядеть это будет так:
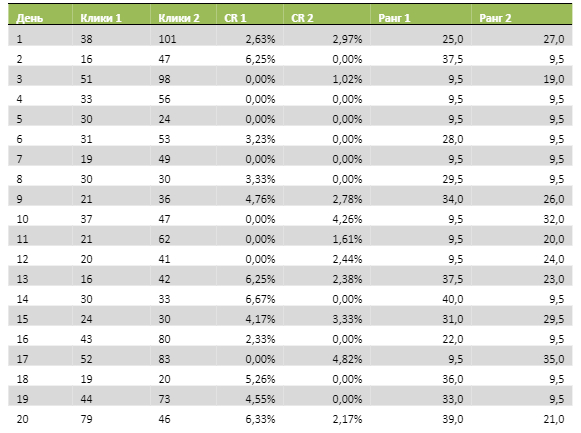
Сумма рангов 1 468,50
Сумма рангов 2 351,50
Uэмп 1 141,5
Uэмп 2 258,5
Umin 141,5

U-критическое 127
Umin > Uкр, различия выборок можно считать несущественными.
Вернемся к сути самого критерия – отражению степени пересечения значений. 18 из 40 значений – это нули. Если бы мы взяли за основу количество конверсий за день, то количество пересечений было бы ещё выше, и минимальное эмпирическое значение U-критерия было бы ещё выше и дальше от критического значения.
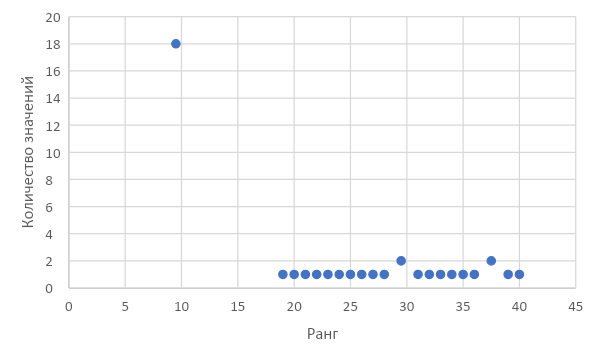
Нет строгого правила относительно количества одинаковых значений в выборке при использовании U-критерия Манна – Уитни. Однако чем больше одинаковых значений в выборке, тем менее информативными будут результаты теста. Другими словами, тест и не должен был выявить различий между выборками из-за недостаточного разнообразия данных.
Заключение
Опираясь на критерии оценки тестов, мы не всегда готовы накапливать необходимый объем данных. Накопление негативного результата и расходов ведет к поспешным выводам об эффективности тех или иных решений.
При этом затрачиваются дополнительные ресурсы, и сам процесс напоминает рулетку. Счетные числовые различия в кампаниях могут быть интуитивно понятны/значимы, если просто в лоб сравнить изменения в метриках между объектами. Так, результат t-теста выше не проходит логическую проверку, как только мы видим одинаковый CPL, несмотря на действительно внушительную разницу в CR. Сама разница в показателях обусловлена CPC – разной аудиторией, по которой кампания обучалась приводить конверсии, либо в пределах величин, выглядящих случайными, в случае с количеством конверсий. В таблице ниже именно относительные величины показателей кампании 2 (тестовой) к кампании 1 (исходной):

В этом же ключе можно рассмотреть таблицу выше как подтверждение вывода, который был сделан с помощью U-критерия. Ведь сам по себе критерий не имеет четкого ограничения по количеству одинаковых значений в выборке.
Таким образом, при небольших ресурсах на тест (или малозначимых тестируемых изменениях) вероятно интереснее отдать совокупный бюджет одной кампании с автостратегией, чем пытаться понять, где лучший заголовок или баннер, чтобы получить таким образом более стабильный результат (необходимый и достаточный объем).
Особенно при условии, что есть уверенность в таргетингах (целевые ключевые слова, ретаргетинг и т. д.). Вдобавок обозначенный в Яндекс Директ объем для стабильной работы в 10 конверсий в неделю выглядит априори заниженным для стабильных результатов, т. е. для деления кампаний в А/Б тест количество должно в несколько раз превосходить, чтобы шансы на достоверность результата были выше.