Особенности работы с большим семантическим ядром
При поисковом продвижении сайта немало времени уходит на работу с семантическим ядром. Если оно состоит из 10-20 запросов или даже из 100-200, то в этом случае затраты труда и времени будут относительно скромными, но при использовании семантического ядра, которое измеряется тысячами слов, как правило возникают сложности. В этом выпуске рассылки мы расскажем, как можно оптимизировать работу со списком продвигаемых запросов из десятков тысяч слов.
Сравнительная характеристика ядер разного размера
Небольшие ядра, количество запросов в которых измеряется десятками, требуют от оптимизатора куда меньше времени, чем ядра из тысяч слов. Это немаловажный фактор, так как многие просто не имеют возможности тратить на продвижение много времени.
Однако с использованием небольшого количества запросов сложно охватить широкую аудиторию в рамках какой-либо тематики. Большое же ядро позволяет собирать значительную долю трафика. Но с другой стороны велик риск того, что в этом случае в ядро просочится большое количество запросов-пустышек, не приносящих никакого полезного трафика. Если же список ключевиков невелик, то его можно тщательно обработать вручную без особых хитростей и исключить такие паразитные запросы.
Казалось бы, небольшое ядро легко можно расширить при необходимости, но это не так – как правило структура сайта изначально заточена под эти запросы, и добавление новых может потребовать серьезных доработок, которые далеко не всегда целесообразны. Если говорить о большом семантическом ядре, то там расширение просто не требуется. Обычно сайты, продвигающиеся по тысячам запросов, изначально создаются с учетом этого, то есть сначала составляется его семантическое ядро, и лишь потом под него пишутся страницы и выстраивается вся структура.
Если семантическое ядро состоит из десятка-двух слов, то нет смысла продвигаться по НЧ-запросам – целесообразно использовать высокочастотные и среднечастотные. Однако они намного дороже низкочастотников, которые используются в обширных семантических ядрах.
Проблемы больших семантических ядер
Безусловно, большие семантические ядра могут быть выгодны, давать большой и относительно недорогой трафик, но у них есть и свои недостатки:
- Требуют много времени от оптимизатора, так как даже на просмотр списка запросов необходимо потратить несколько часов.
- Специалисту нужно вникать в тематику и знать особенности конкретной сферы бизнеса, чтобы эффективно работать с ядром.
- Отсутствие необходимых инструментов для работы со списком запросов.
Принципы составления и обработки семантического ядра
Источником для семантического ядра могут послужить сервисы по сбору статистики, например, «Яндекс.Метрика», Google Analytics или wordstat.yandex.ru. Необходимый материал могут дать каталоги продукции, списки и описания товаров и любая другая информация, которую может предоставить клиент. Расширить список также может помочь анализ кампаний конкурентов.
Для проверки полноты первичного ядра можно воспользоваться простым способом: достаточно ввести в wordstat.yandex.ru какое-нибудь слово, характеризующее тематику. Например, частотность по слову «плитка» в московском регионе – более 600 тысяч показов в месяц. Запросов же состоящих только из одного слова «плитка» насчитывается всего около 0,5% от общего количества, что очередной раз доказывает, что по подобным словам продвижение практически бессмысленно.
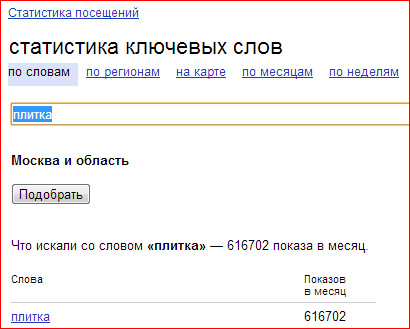
Запросов со словом «плитка» плюс еще одно любое слово насчитывается около 15%, с двумя словами – 20%, с тремя – около 16%, далее частотность убывает. Но даже запросы «плитка + 6 слов» могут давать неплохой трафик.
В итоге получается довольно много запросов, но из них значительная часть не подойдет для продвижения, так как она не относится к нужной тематике. Чтобы убрать «мусор» можно воспользоваться:
- отсевом по стоп-словам (как стандартными «скачать», «форум» и т.д., так и специфическими для конкретной тематики);
- удалением слов с ненужными геозапросами;
- проверкой корректности слов по версии поисковой системы (опечатки, орфографические ошибки);
- отбор по точной частотности, по соотношению частотностей.
Но при этом в ядре останутся дорогие ВЧ- и СЧ-запросы и не будет слов, связанных с новыми товарами и услугами, которые тоже необходимо учитывать при продвижении.
Еще одним сложным моментом при работе с ядром является специфика тематики. Для эффективного отбора нужных запросов нужно хорошо разбираться в терминологии той сферы, которой посвящен сайт. Что делать в таком случае? Можно уточнить у заказчика или проверить самому, но даже если запросов будет 1000, то для выполнения этой задачи потребуется огромное количество времени. Одно из самых простых решений – проанализировать поисковую выдачу по интересующему запросу на предмет наличия в ней основных ключевых запросов из конкретной тематики. Обычно в сниппетах на первой странице выдачи можно встретить 2-3 десятка вхождений таких слов.
Для распределения запросов по группам и формирования необходимой структуры сайта можно проанализировать ТОП конкурентов и на основе полученных данных структурировать список ключевых слов.
Автоматизация процесса
Очевидно, что ручной процесс подбора ключевых слов занимает довольно много времени, но оптимизатору могут помочь специальные инструменты, которые позволяют автоматизировать операции по составлению семантического ядра. Одним из таких сервисов является встроенный модуль по подбору слов в Системе SeoPult. Он доступен пользователям на вкладке «Слова».
В основном блоке сверху доступны два типа подбора слов:
- «слова близкие к ТОПу» — Система предлагает добавить к продвижению те запросы, которые находятся уже близко к лидирующим позициям (от 11-й до 50-й);
- «из счетчика» — для просмотра слов, которые предлагает этот подборщик, необходимо подключить один из сервисов статистики (Liveinternet, «Яндекс.Метрика» или Google Analytics), Система покажет информацию по запросам, по которым были зарегистрированы переходы на ваш сайт.
В SeoPult есть несколько типов подборщиков ключевых слов:
- «Авто» – не требует введения основных запросов, а подбирает слова на основе анализа контента страницы.
- «Семантика» – этот способ подбора может расширить и углубить семантическое ядро.
- Wordstat – подбор СЧ- и НЧ-запросов с использованием статистики сервиса wordstat.yandex.ru.
- СЧ – подбор среднечастотных запросов на основе тематического кластера уже введенных слов.
- СЧ+НЧ – подбор СЧ-запросов и добавление низкочастотных слов на основе статистики Wordstat.
Ценность подборщиков слов в SeoPult заключается в том, что оптимизатор сразу видит статистику слов, прогнозы по переходам и стоимости продвижения, а также геозависимость запросов. Это существенно экономит время при составлении семантического ядра.
Источник
Информационная рассылка SeoPult
Выпуск №125: Особенности работы с большим семантическим ядром
Подписаться на рассылку SeoPult
| Выводы Практика поисковой оптимизации показывает, что часто гораздо выгоднее полагаться на стратегию продвижения по большому количеству низкочастотных запросов, а не растрачивать бюджет на ожесточенную борьбу с конкурентами по высокочастотным словам. Но для составления большого семантического ядра, которое может состоять из десятков тысяч ключевиков, необходимо применять особые приемы в работе, чтобы сократить временные затраты. |